在 Hugo 中显示 LaTeX 的问题及其解决方案
我有另外一个 Blogdown 写的博客,但因为厌倦了对 R 的依赖于是策划了很久迁移回 vanilla Hugo。然而,每当我想在 Hugo 生成的网站中使用 LaTeX 的时候,就又想起 Blogdown 的好来。
请试想您想要写这个非常简单的分段方程:(图片来自 KaTeX 的在线预览)
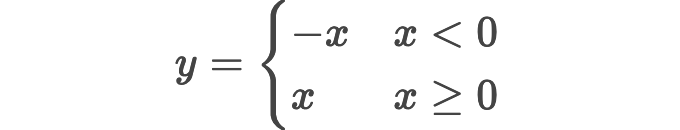
$$y = \begin{cases}-x & x<0 \\ x & x\geq 0 \end{cases}$$
但却得到了这样的结果:
$$y = \begin{cases}-x & x<0 \ x & x\geq 0 \end{cases}$$
这是因为 Goldmark 在渲染双斜杠 \\ 的时候会将其更改为单斜杠,导致所有换行失效。无论使用 MathJax 还是 KaTeX 作为渲染引擎,都会出现这个问题。
以下讨论提到了这个问题:
- How to render math equations properly with KaTeX - support - HUGO
- Add MathJax build support – post-hugo processing · Issue #6694 · gohugoio/hugo
市面上流传着各种解决方案,例如:
- Render LaTeX math expressions in Hugo with MathJax 3 · Geoff Ruddock
- jmooring/hugo-testing at hugo-forum-topic-40998
- litao91/goldmark-mathjax: A mathjax extension for goldmark
- graemephi/goldmark-qjs-katex: Goldmark + KaTeX
那么 Blogdown,以及整个 RMarkdown,是怎么解决这个问题的呢?答案是猴子补丁:The Best Way to Support LaTeX Math in Markdown with MathJax - Yihui Xie | 谢益辉。
尽管如此,这依然是我目前见过的最优雅和省事(以及保持 Markdown 文件中的 LaTeX 语法正确,很重要!)的方案了。
Blogdown 整体的工作流程大概是,先把 .rmd 文件运算及渲染成 .md 文件,然后再使用 Hugo 渲染成 .html 文件。
这个解法的核心在于,在第一步渲染时,先把所有数学公式都假装成代码,以此保留双斜杠;在第二步之后,展示网页时,使用数学引擎之前,提前注入 JavaScript 把假装成代码的外壳(<code>...</code>)去掉,这样就能正确显示公式了。
代码如下: yihui/hugo-lithium/math-code.js
(function() {
var i, text, code, codes = document.getElementsByTagName('code');
for (i = 0; i < codes.length;) {
code = codes[i];
if (code.parentNode.tagName !== 'PRE' && code.childElementCount === 0) {
text = code.textContent;
if (/^\$[^$]/.test(text) && /[^$]\$$/.test(text)) {
text = text.replace(/^\$/, '\\(').replace(/\$$/, '\\)');
code.textContent = text;
}
if (/^\\\((.|\s)+\\\)$/.test(text) || /^\\\[(.|\s)+\\\]$/.test(text) ||
/^\$(.|\s)+\$$/.test(text) ||
/^\\begin\{([^}]+)\}(.|\s)+\\end\{[^}]+\}$/.test(text)) {
code.outerHTML = code.innerHTML; // remove <code></code>
continue;
}
}
i++;
}
})();用这套代码还有一个额外的好处,就是可以直接使用美元符号分隔数学公式,而不需要额外设置 KaTeX delimiter 了。
当然,这也不是完全没有任何瑕疵的。比如,如果我是真的想用代码框展示 LaTeX 源码,而不是渲染后的公式,此时就会很尴尬了。为了允许这种情况,修改代码如下: loikein/hugo-book/latex-fix.js
(function() {
var i, text, code, codes = document.getElementsByTagName('code');
for (i = 0; i < codes.length;) {
code = codes[i];
if (code.parentNode.tagName !== 'PRE' && code.childElementCount === 0 && !(code.classList.contains("nolatex")) ) {
text = code.textContent;
if (/^\$[^$]/.test(text) && /[^$]\$$/.test(text)) {
text = text.replace(/^\$/, '\\(').replace(/\$$/, '\\)');
code.textContent = text;
}
if (/^\\\((.|\s)+\\\)$/.test(text) || /^\\\[(.|\s)+\\\]$/.test(text) ||
/^\$(.|\s)+\$$/.test(text) ||
/^\\begin\{([^}]+)\}(.|\s)+\\end\{[^}]+\}$/.test(text)) {
code.outerHTML = code.innerHTML; // remove <code></code>
continue;
}
}
i++;
}
})();然后在写到需要展示 LaTeX 源码的时候,就写成 <code class="nolatex">...</code>。当然,还必须在 config.yaml 里设置允许 raw HTML:
markup:
goldmark:
renderer:
unsafe: true写到这里您可能想问了,这如果用 vanilla Hugo,哪儿来的 <code> 呢?……答案是手动添加。
好吧,其实也没那么手动。以 display mode 为例,在文本编辑器中,在网站的根文件夹内使用正则查找 (\$\$)((.|\n)*?)(\$\$),然后打开找到的文件,仔细检查后,逐一正则替换为 \`\$\$\2\$\$\` 就可以了。
这个博客上我尽量避免写太多数学公式,所以也没打算在这里实装,但凑一篇技术文章还是可以的。以上。